Home
Biophysical Motivation
Installation
Quick Start Jupyter Notebook
Quick Start command line
Examples
Publications
MolClustPy
Python package to characterize the multivalent biomolecular clusters
When the affinities of the individual molecular interactions are relatively weak, multivalent clusters maintain their integrity but allow various molecular compositions (Mayer et al, 2009), so multiple simulation runs are required to determine the average behavior of such bimolecular system. MolClustPy is a Python package to perform multiple stochastic simulation runs using NFsim (Network-Free stochastic simulator, Sneddon et al, 2011) and characterize distribution of cluster sizes, molecular composition, and bonds across molecular clusters and individual molecules of different types.
Please note that NFsim is a non-spatial simulator, so it does not account for excluded volume and non-physical crosslinking when generating molecular complexes.
Graphical Summary
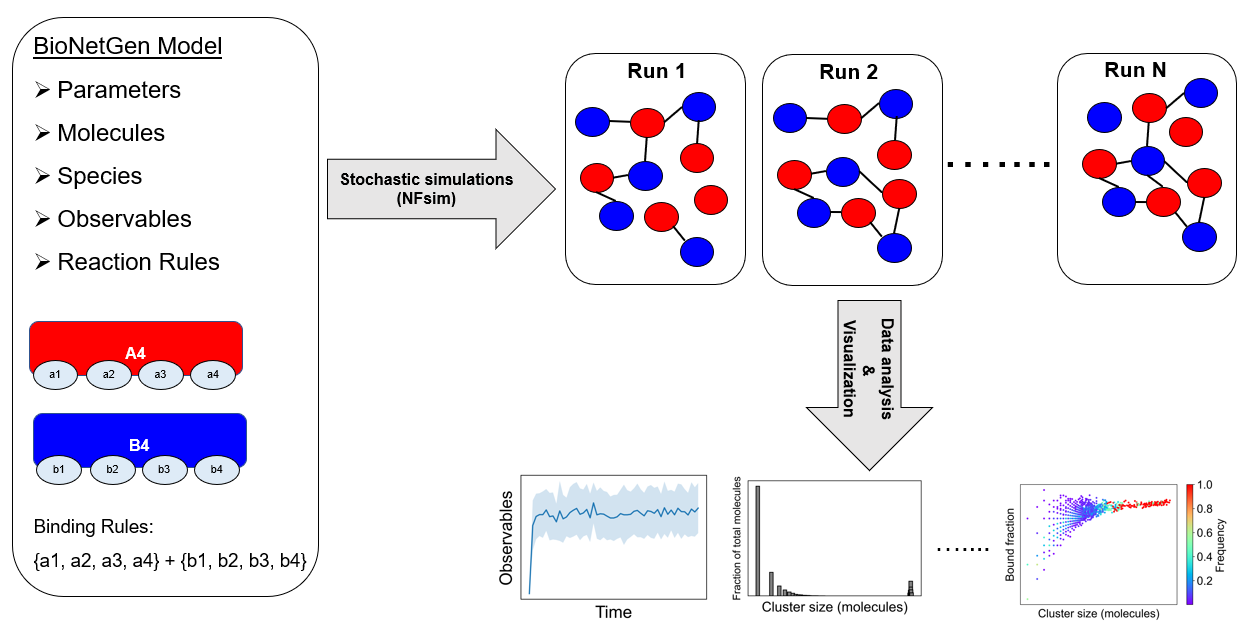
A model needs to be defined in the BioNetGen Language (BNGL). In this example, a tetravalent molecular pair (A4 and B4) is shown where any of the a-sites can bind to any of the b-sites. Once we define the model, we run multiple stochastic runs using NFsim. Molecular clusters (networks) would form in a stochastic way across these runs. We assemble these clusters and analyze average properties like cluster size, composition, binding saturation etc.
Detailed Workflow
Input: rule-based model specification in BioNetGen Language (BNGL) format
Systems with combinatorial complexity require a special kind of modeling technique called Rule based modeling (RBM) (Blinov et al., 2004). In this approach, a molecule is modelled as an object with multiple sites.
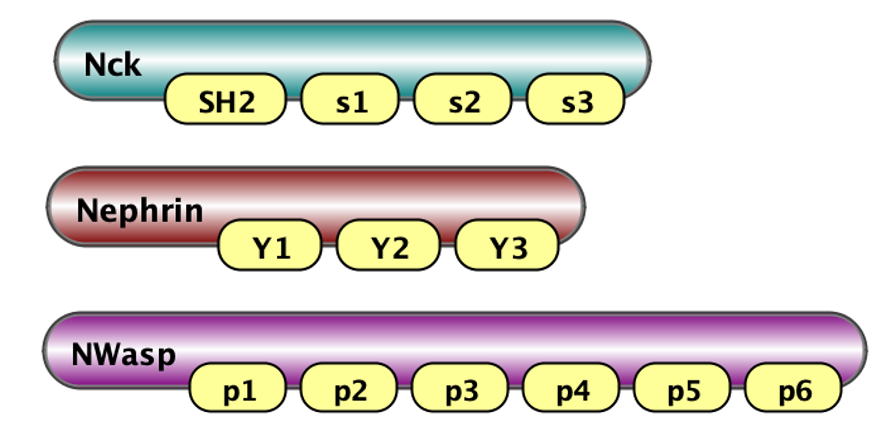 |
Nck(SH2,s1,s2,s3) Nephrin(Y1,Y2,Y3) NWasp(p1,p2,p3,p4,p5,p6) |
Here on the left we show visaulization of molecules in VCell notations (Schaff et al., 2016): Nck has 4 binding sites - one SH2 and three SH3 (called s1, s2, s3); Nephrin has three tyrosine binding sites Y1, Y2 and Y3; and N-Wasp has 6 PRM binding sites coded p1, p2, ..p6. On the right we show how these molecules are defined in BNGL notations.
A set of rules then specifies the interactions among molecules.
 |
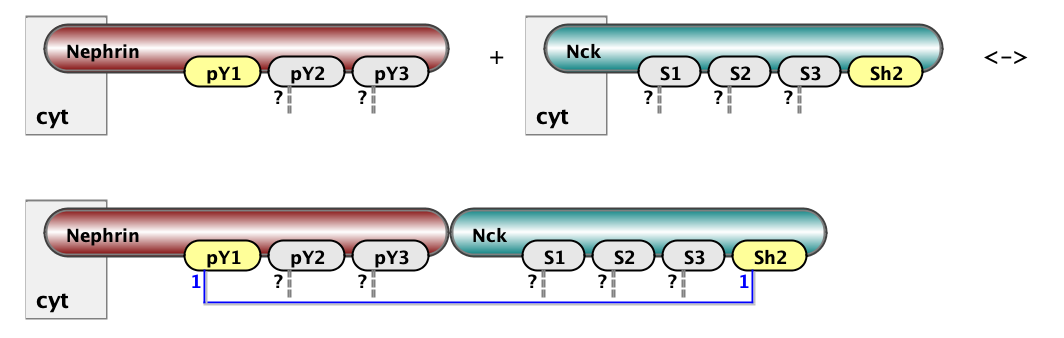 |
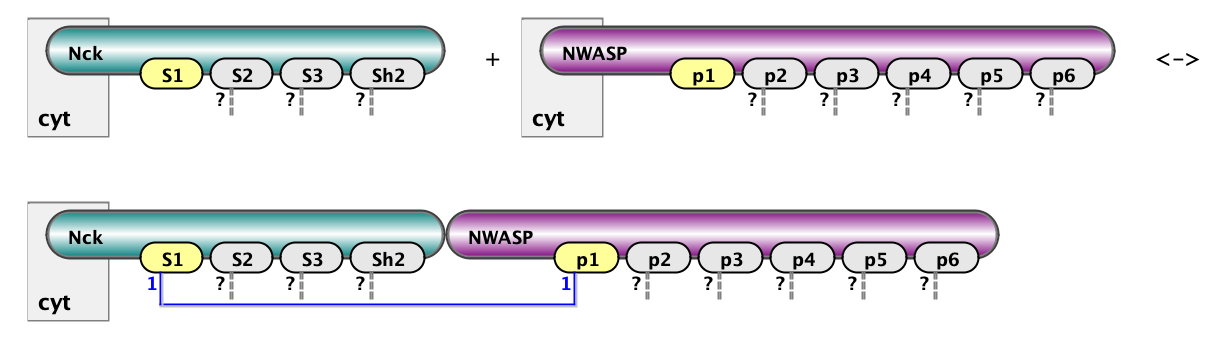
Here we show two example of rules: on the left is binding of Nck to NWasp via interaction of s1 site with p1. On the right is binding of Nephrin to Nck via interaction of Y1 site of Nephrin with SH2 domain of Nck. The full set of rules consists of 18 rules of the first type (6x3) and 3 rules of the second type (1x3). Below are the same rules written in BNGL notations. kon and koff are on and off rate constants for mass-action kinetic law - default kinetic law in BioNetGen.
Nck(s1) + NWASP(p1) <-> Nck(S1!1).NWASP(p1!1) kon_23, koff_23
Nephrin(pY1) + Nck(Sh2) <-> Nephrin(pY1!1).Nck(Sh2!1) kon_12, koff_12
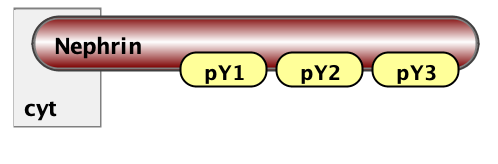
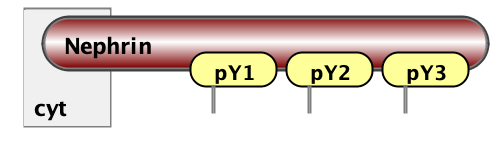
Finally, the essential part of model specification is the observables - the pattern that specify properties of molecular complexes we’d like to track. Below are three observables - free Nephrin (no site is bound), fully bound Nephrin (all sites are bound), and a complex of Nck and NWasp with undefined connectivity. Underneath are the same observables written in BNGL notations.
 |
 |
 |
Molecules free_Nephrin Nephrin(pY1,pY2,pY3)
Molecules fully_bound_Nephrin Nephrin(pY1!+,pY2!+,pY3!+)
Molecules cluster_nck_nw Nck().NWASP()
The results of a single NFsim simulation are 1) timecourses for all observables; and (2) the file with the final set of molecular complexes. Below is a snapshot of a rather small molecular cluster and the beginning of BNGL string describing it:

NWASP(p1!1,p2,p3,p4,p5!2,p6!3).Nck(S1!1,S2,S3!4,Sh2).Nck(S1!2,S2!5,S3,Sh2)...
Output: statistical characterization of molecular clusters
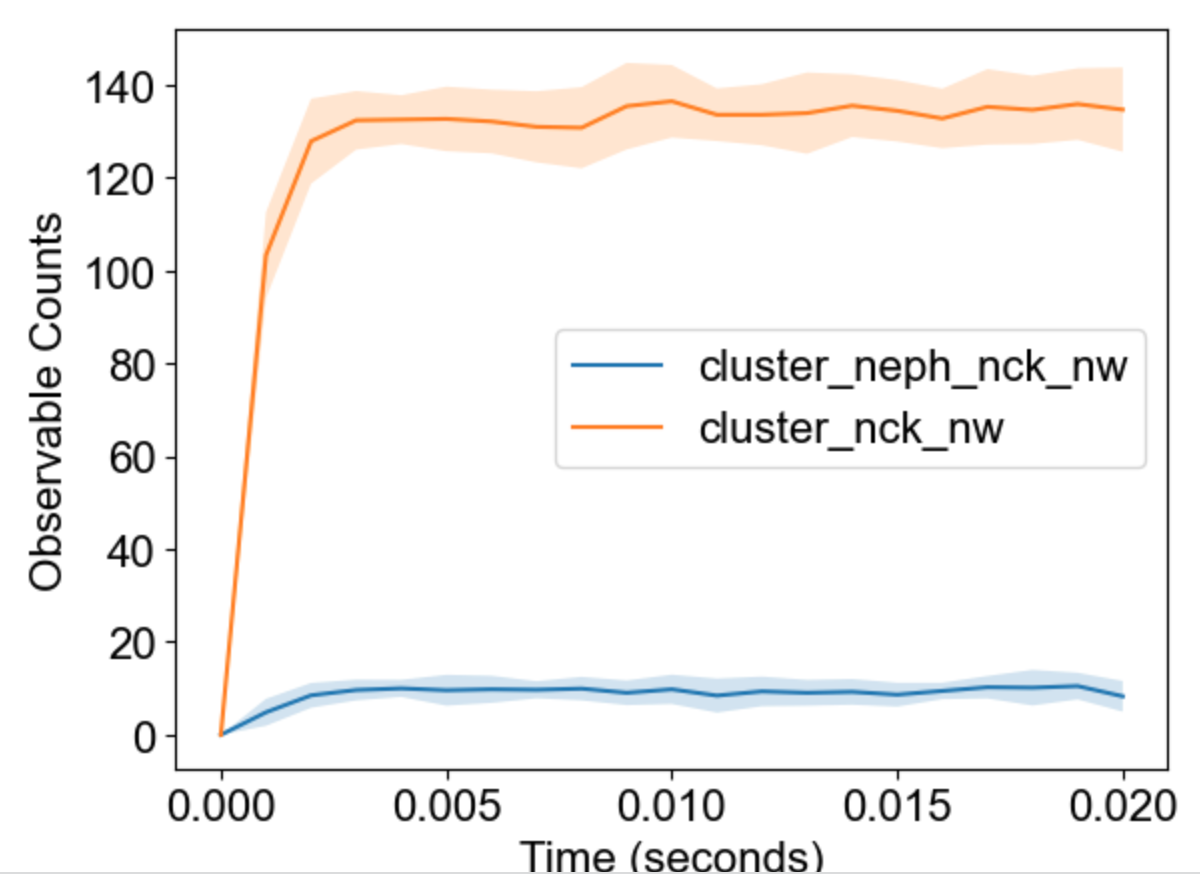
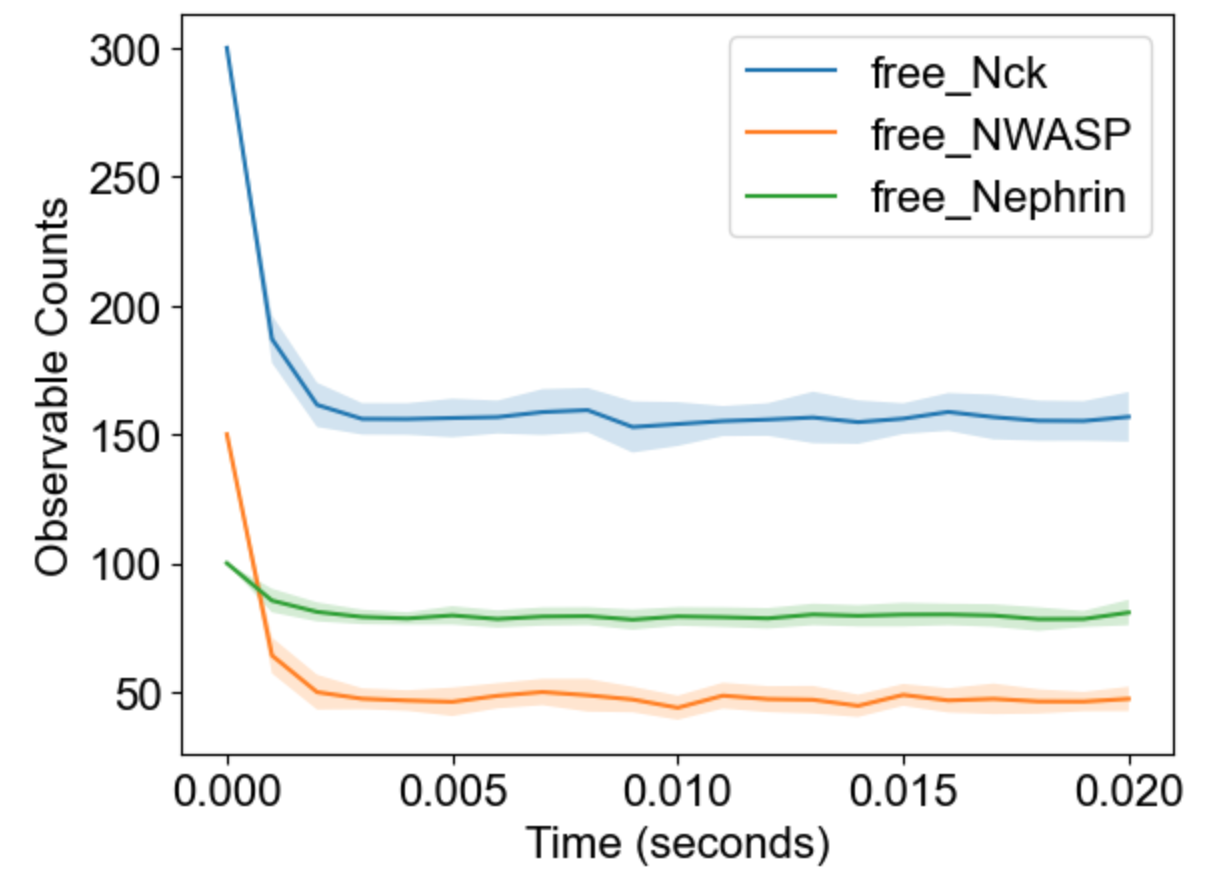
MolClustPy is a Python package that can be run as a command line or as a Jupyter notebook. It simulates the BNGL file several (user-defined) number of times and outputs visualization of simulation results. Below the model specified in ‘./test_dataset/Nephrin_Nck_NWASP_high_concentration.bngl’ file is simulated numRuns times for 20 milliseconds (t_end).

The package will analyze multiple runs and display envelope (min-max) for timecourses of observables:
 |
 |
Global properties of clusters
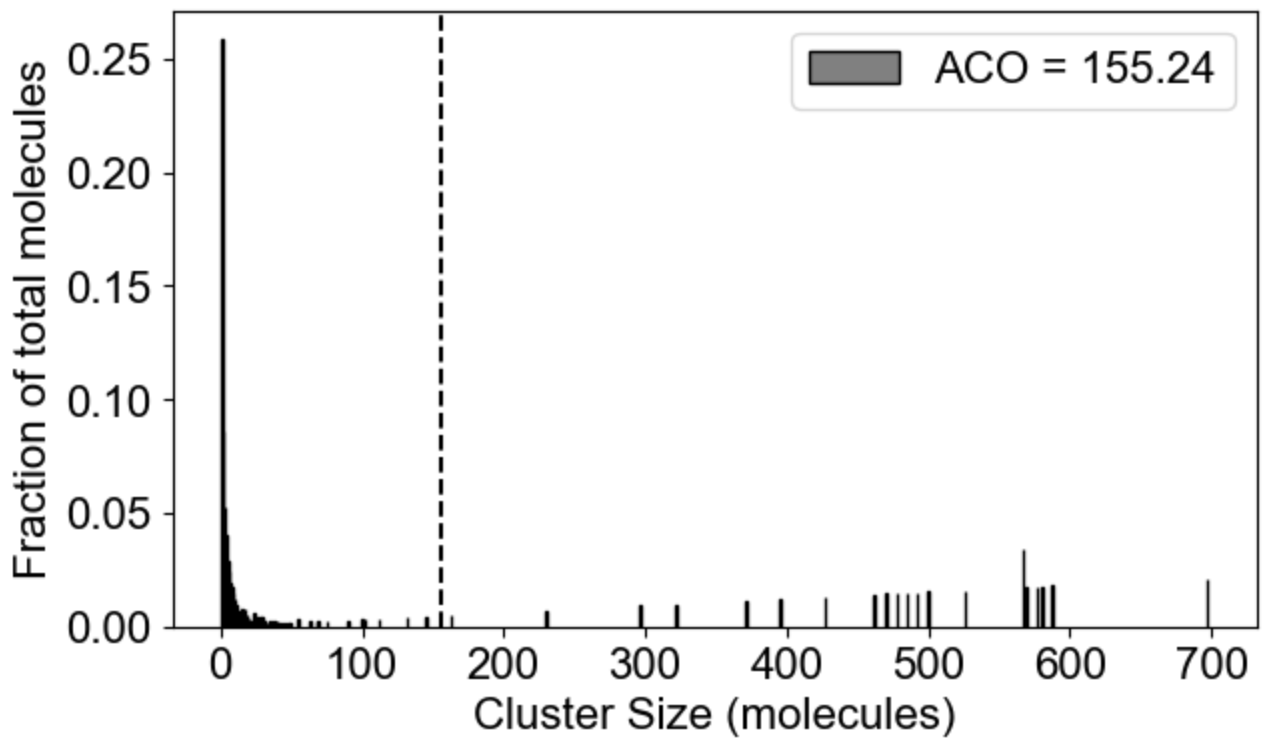
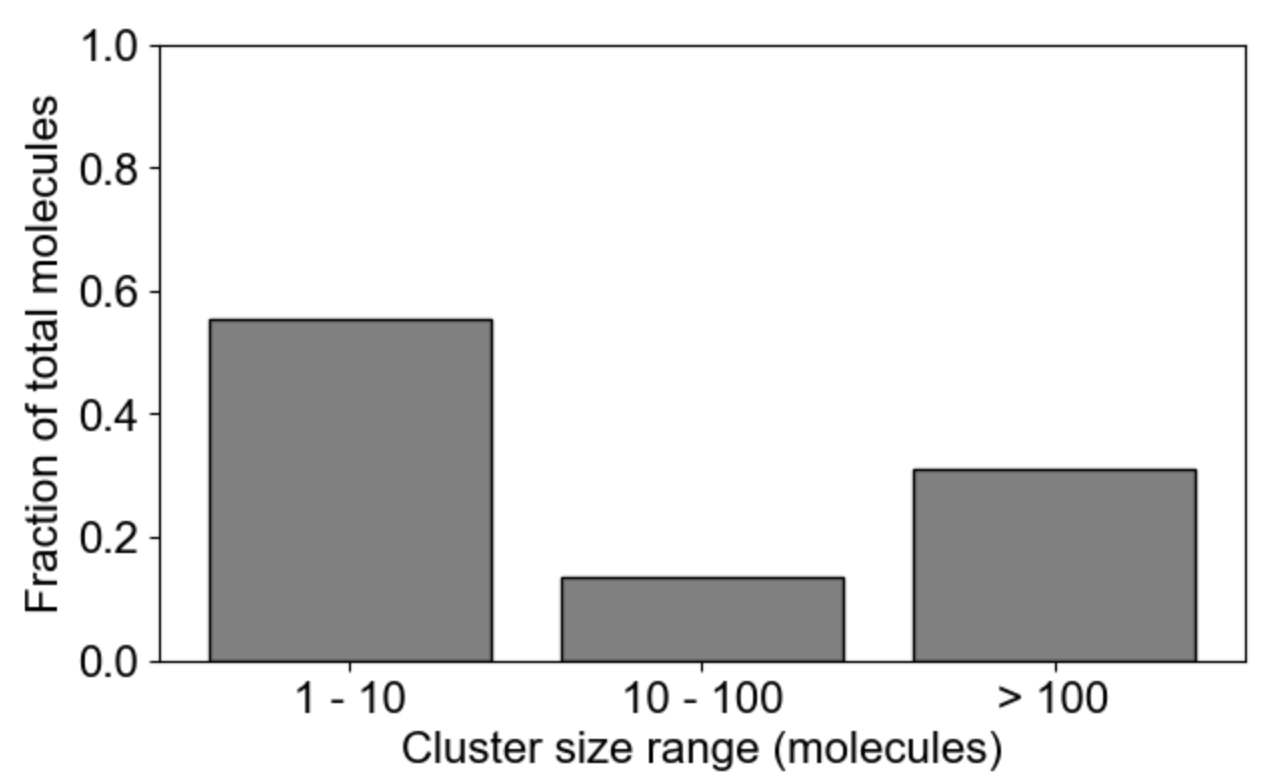
MolClustPy will analyze and plot average occupancy (fraction of total molecules in clusters of different sizes, and the the average cluster size among all clusters weighted by number of molecules), as well as binning of clusters by size: here we see the fraction of molecules in small (1-10 molecules), medium (10-100 molecules) and large (more than 100 molecules) clusters.
 |
 |
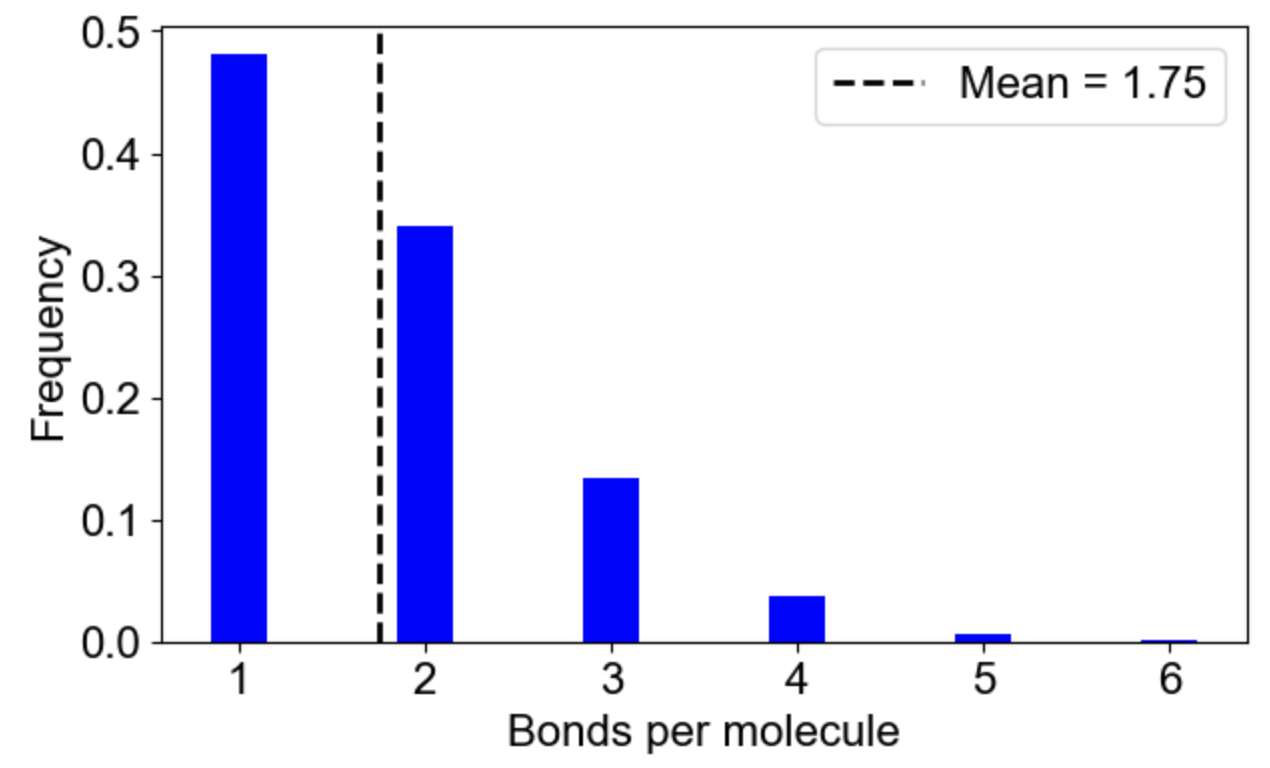
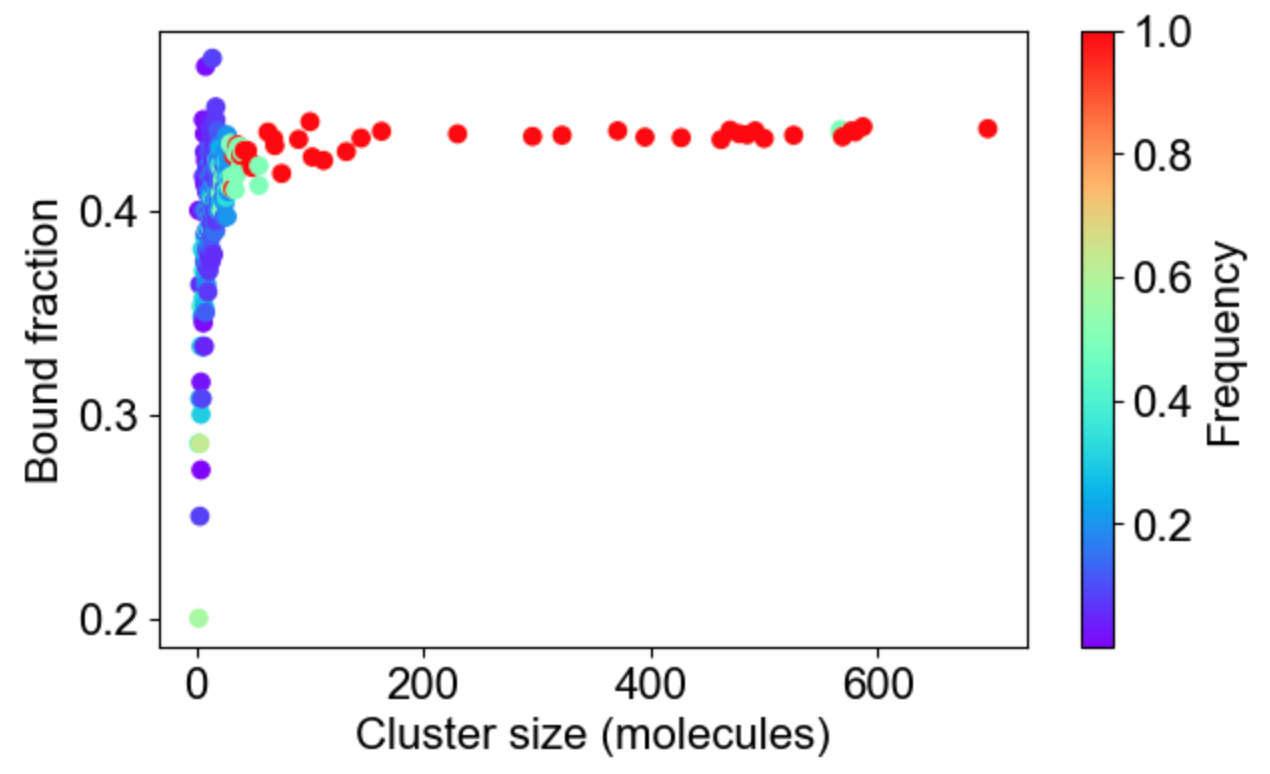
MolClustPy will analyze and plot the frequency of molecules in clusters with a given number of bonds. On the left is a plot indicating that almost 48% of all molecules have very weak connectivity (one bond), while there are few molecules that serve as hubs with 3, 4, 5 or even 6 (there are NWasp molecules) bonds. An average molecule has 1.75 bonds. On the right the same cluster distribution is plotted as bound fraction of molecules per cluster size. One can see that large clusters tend to be unique (red dots) while small clusters come in a variety of compositions. What is more important, the bound fraction converges to a fixed value for larger clusters, meansing binding sites are saturated up to 42% maximum.
 |
 |
Molecule-specific properties of clusters
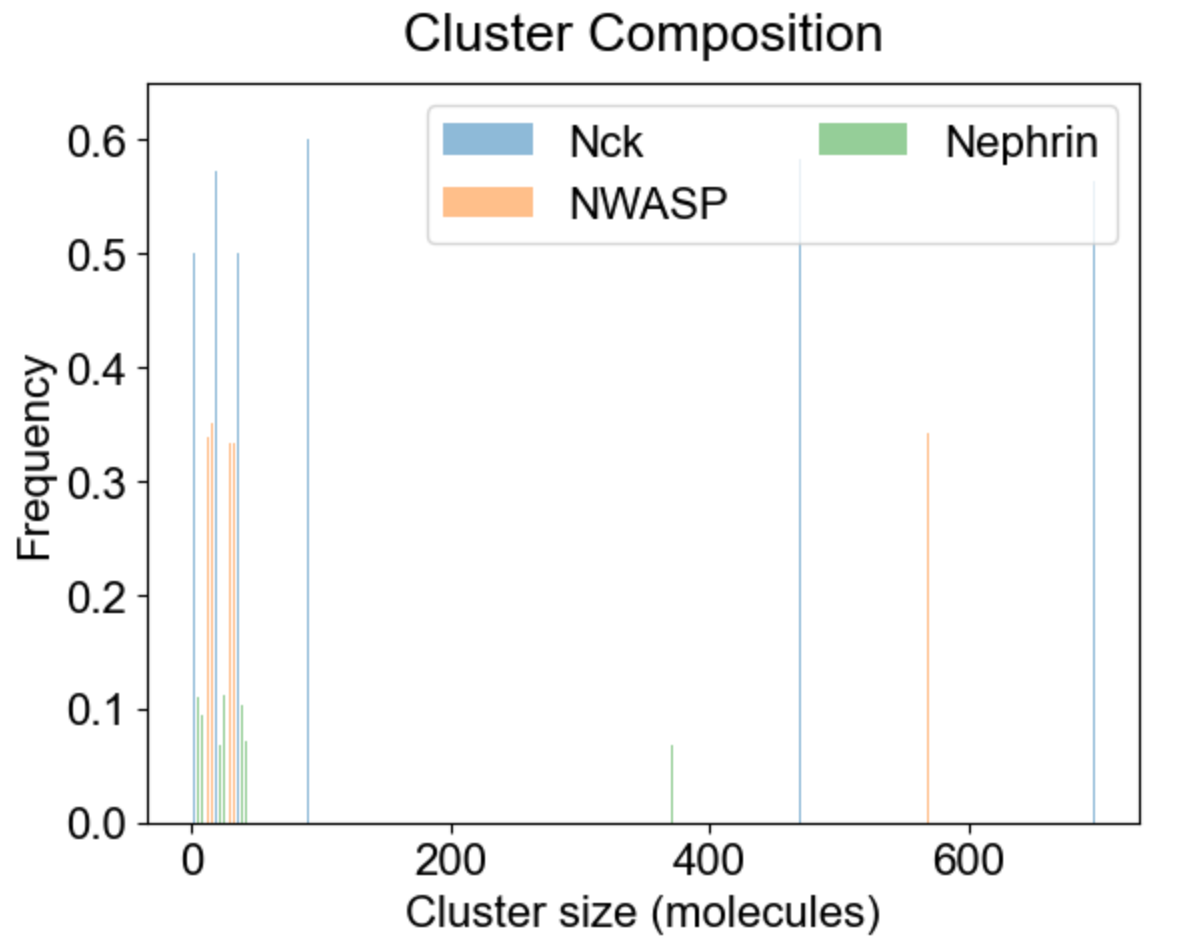
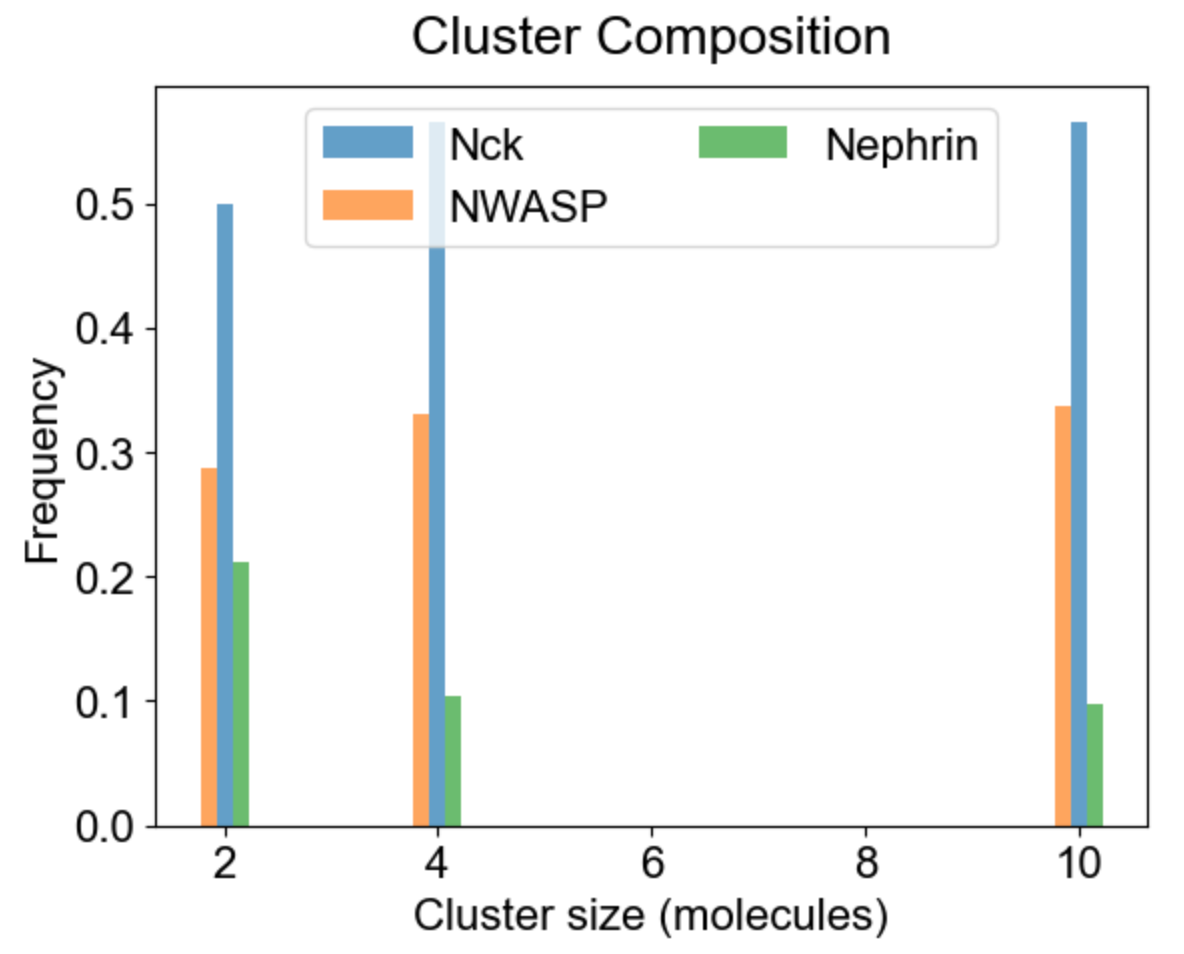
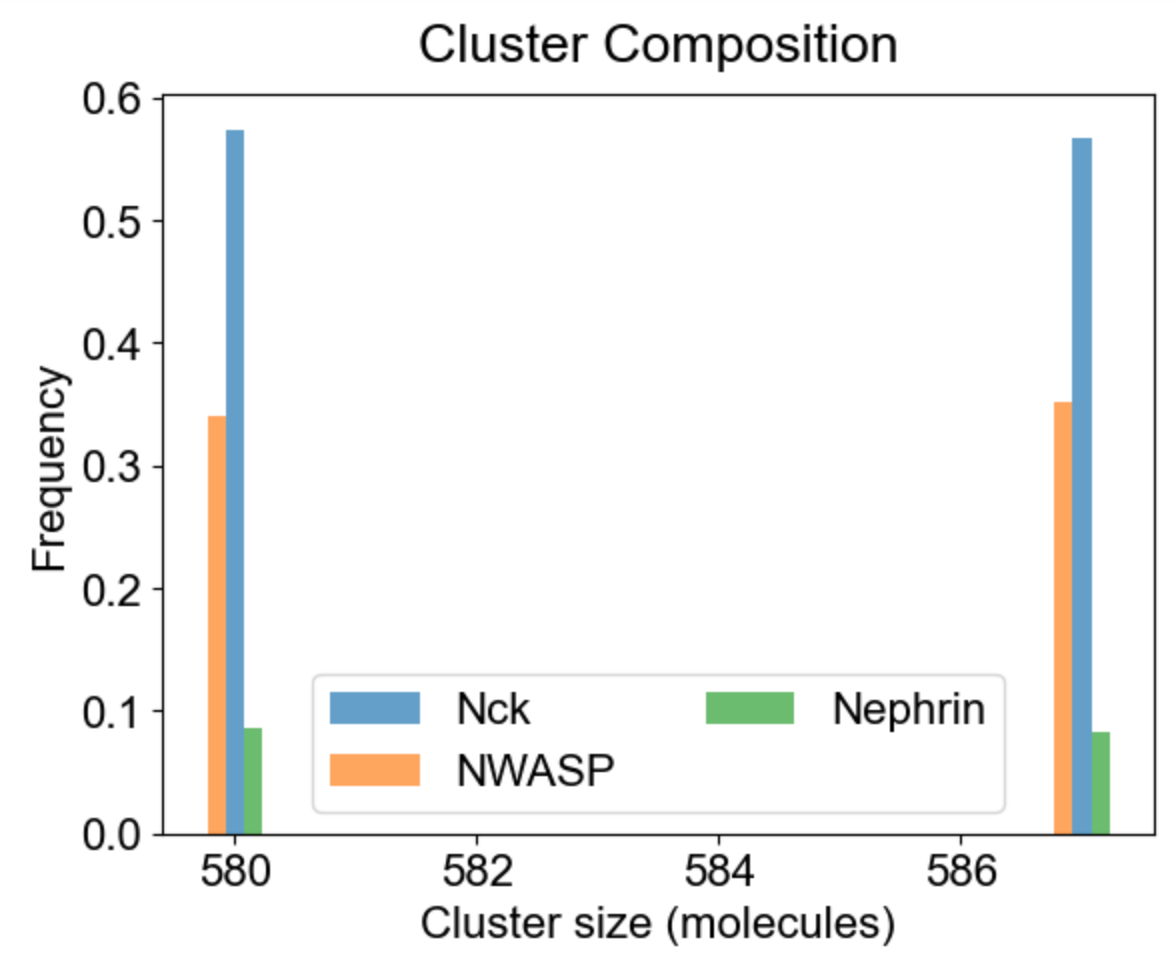
Apart from the cluster size distribution, it might be useful to know the composition of the clusters with respect to individual molecular types. On the left we plot the relative fraction of each molecular type within a given cluster size. Note that the sum of all molecular fractions for a given cluster size should be equal to one. For large cluster size range, it might be of interest to inspect composition of a list of special clusters - either a set of small clusters (2,4,10 - middle plot), or a set of large clusters (580, 587 - right plot).
 |
 |
 |
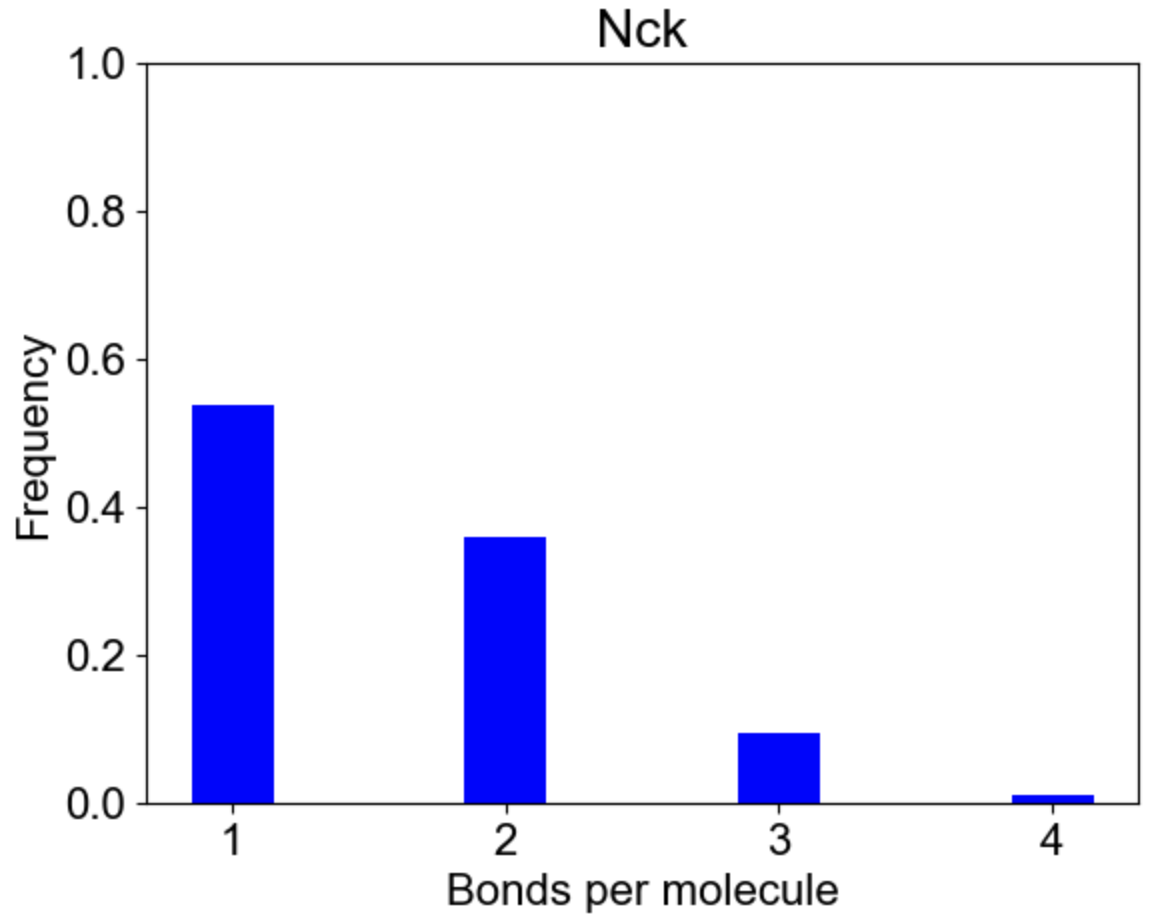
Finally, MolClustPy can plot bonds distribution for a specific molecular type, e.g. how cross-linked or saturated Nck molecules are in the system? Each Nck can have 1 to 4 bonds:
 |
Data storage for post-processing
All the simulation outputs (gdat and species files) of NFsim is written to the folder with the same name as the BNGL file. The statistical data generated by MolClustPy and used to plot figures is stored in pyStat folder within the model folder.